本文共 2570 字,大约阅读时间需要 8 分钟。
AI前线导读: 近日,数据科学网站KDnuggets评选出了顶级Python库Top15,领域横跨数据科学、数据可视化、深度学习和机器学习。
和往常一样,我们需要你们的意见,如果你觉得项目没有上榜单是不公平的,或者对我们的选择有异议,请在评论求留言让我们知道。
更多干货内容请关注微信公众号“AI前线”(ID:ai-front)
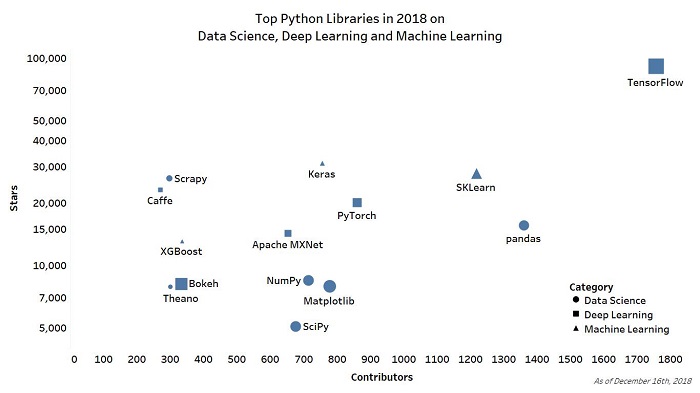
1 TensorFlow(贡献者:1757,贡献:25756,Stars:116765)
“TensorFlow是一个使用数据流图进行数值计算的开源软件库。图形节点表示数学运算,而图形边缘表示在它们之间流动的多维数据阵列(张量)。这种灵活的体系结构使用户可以将计算部署到桌面、服务器或移动设备中的一个或多个CPU/GPU,而无需重写代码。 ”
GitHub地址:
2 pandas(贡献者:1360,贡献:18441,Stars :17388)
“pandas是一个Python包,、供快速,灵活和富有表现力的数据结构,旨在让”关系“或”标记“数据使用既简单又直观。它的目标是成为用Python进行实际,真实数据分析的基础高级构建块。”
GitHub地址:
3 scikit-learn(贡献者:1218,贡献者:23509,Stars :32326)
“scikit-learn是一个基于NumPy,SciPy和matplotlib的机器学习Python模块。它为数据挖掘和数据分析提供了简单而有效的工具。SKLearn所有人都可用,并可在各种环境中重复使用。
GitHub 地址:
4 PyTorch(贡献者:861,贡献:15362,Stars:22763)
“PyTorch是一个Python包,提供两个高级功能:
- 具有强大的GPU加速度的张量计算(如NumPy)
- 基于磁带的自动编程系统构建的深度神经网络
你可以重复使用自己喜欢的Python软件包,如NumPy,SciPy和Cython,以便在需要时扩展PyTorch。”
GitHub地址:5 Matplotlib(贡献者:778,贡献:28094,Stars :8362)
“Matplotlib是一个Python 2D绘图库,可以生成各种可用于出版品质的硬拷贝格式和跨平台交互式环境数据。Matplotlib可用于Python脚本,Python和IPython shell(例如MATLAB或Mathematica),Web应用程序服务器和各种图形用户界面工具包。”
GitHub地址:
6 Keras(贡献者:856,贡者:4936,Stars :36450)
“Keras是一个高级神经网络API,用Python编写,能够在TensorFlow,CNTK或Theano之上运行。它旨在实现快速实验,能够以最小的延迟把想法变成结果,这是进行研究的关键。”
GitHub地址:
7 NumPy(贡献者:714,贡献:19399,Stars:9010)
“NumPy是使用Python进行科学计算所需的基础包。它提供了强大的N维数组对象,复杂的(广播)功能,集成C / C ++和Fortran代码的工具以及有用的线性代数,傅里叶变换和随机数功能。
GitHub地址:
8 SciPy(贡献者:676,贡献:20180,Stars:5188)
“SciPy(发音为”Sigh Pie“)是数学、科学和工程方向的开源软件,包含统计、优化、集成、线性代数、傅立叶变换、信号和图像处理、ODE求解器等模块。”
GitHub地址:
9 Apache MXNet(贡献者:653,贡献:9060,Stars:15812)
“Apache MXNet(孵化)是一个深度学习框架,旨在提高效率和灵活性,让你可以混合符号和命令式编程,以最大限度地提高效率和生产力。 MXNet的核心是一个动态依赖调度程序,可以动态地自动并行化符号和命令操作。”
GitHub地址:
10 Theano(贡献者:333,贡献:28060,Stars :8614)
“Theano是一个Python库,让你可以有效地定义、优化和评估涉及多维数组的数学表达式。它可以使用GPU并实现有效的符号区分。”
GitHub地址:
11 Bokeh(贡献者:334,贡献:17395,Stars :8649)
“Bokeh是一个用于Python的交互式可视化库,可以在现代Web浏览器中实现美观且有意义的数据视觉呈现。使用Bokeh,你可以快速轻松地创建交互式图表、仪表板和数据应用程序。”
GitHub地址:
12 XGBoost(贡献者:335,贡献:3557,Stars:14389)
“XGBoost是一个优化的分布式梯度增强库,旨在变得高效、强大、灵活和便携。它在Gradient Boosting框架下实现机器学习算法。XGBoost提供了梯度提升决策树(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题,可以在主要的分布式环境(Hadoop,SGE,MPI)上运行相同的代码,并可以解决数十亿个示例之外的问题。”
GitHub地址:
13 Gensim(贡献者:301,贡献:3687,Stars :8295)
“Gensim是一个用于主题建模、文档索引和大型语料库相似性检索的Python库,目标受众是自然语言处理(NLP)和信息检索(IR)社区。”
GitHub地址:
14 Scrapy(贡献者:297,贡献:6808,Stars :30507)
“Scrapy是一种快速的高级Web爬行和Web抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于从数据挖掘到监控和自动化测试的各种用途。”
GitHub地址:
15 Caffe(贡献者:270,贡献:4152,Stars :26531)
“Caffe是一个以表达、速度和模块化为基础的深度学习框架,由伯克利人工智能研究(BAIR)/伯克利视觉与学习中心(BVLC)和社区贡献者开发。”
GitHub地址:
参考链接:
转载地址:http://nhxal.baihongyu.com/